2026-04-25
社工信息收集
我去翻某个学校的公众号看了下,有一些公示的信息,比如:
- 奖学金名单公示。这种一般有姓名和学号,或者班级学院信息
- 学生或者教师任职公示。这种一般也有学号工号信息,有的还有电话
- 有些没有很严格的安全措施的站点,可能安全限制很薄弱,明文传入登陆账号密码等
再就是进行海底捞了,抖音、小红书、贴吧、频道这种公众社交平台,很大概率碰见那些放出来自己录取信息的(最好还是不要在网上透露太多信息)
今天就是在抖音找到的,这个小妹妹呢放出来了自己的录取信息,但是身份证号都只遮住了后四位,这种打码等于没打码
姓名也露出了最后一位,然后看了下发布信息,四月多的录取信息,再去看了看这学校的公众号,好家伙,居然是单招考试,而且还发了录取名单,这还说啥,直接找,最后通过她名字最后一个字和专业找到她名字和考生号
还有个小弟弟的信息也被我收集了,他露出了身份证号前六位,还有最后一位,他的名字和录取专业,他也是今年单招的,所以我也拿到他考生号了
爆破登录系统
现在知道了她的考生号、身份证号除了后四位,那么需要找个法子去得到全部的身份证号。
正好他们这个学校单招有个平台,通过考生号/身份证号后六位作为账户密码登录,我在想,其实很多这种小平台可能就在某些时候用用,它的检验不会很严格,而且可能不会对发包次数做限制。
我随便输入了点东西,果然是明文传输,这样就好办了,后四位直接爆破,最后会根据返回包长度进行筛选,因为只要是不正确的返回包长度都是一样的,都显示用户名或者密码错误,正确的就会302跳转。
登陆进去可以看到这小妹妹照片、考生号、身份证号、电话号码、家庭住址
很可惜这个系统应该是只拿来查单招成绩了,没有别的服务,一时半伙也没发现什么漏洞点,不过我没拿工具扫,都是眼睛找的,可能到时候看那工具能不能找到点啥头绪
这个小弟弟的信息爆破就有点麻烦了,但是也被我爆出来了。
爆破的点在哪呢,在查询单招信息的位置有一个忘记密码,我们点忘记密码,这里会让输入考生号和身份证号,考生号我们知道了,那怎么知道身份证号呢,这里就是爆破的位置了,因为如果两个号对应正确就会返回密码,那开始构造请求。首先我们要定位一下他哪一年出生的,根据这个同龄人推断,他也就是07或者08的,看了下抖音主页的信息,标的18岁,而且他是4.03就过了科目一,那么他很大概率是07下半年或者08前三个月的范围内了,我先爆破08上半年的时间,爆破到一半就爆破出来了,这样这个小弟弟的信息我们也拿到了。
这里爆破小弟弟的密码应该直接从登陆界面爆破的,因为知道最后一位了,就爆破31*1000次就出来了,不过当时搞到后面就搞忘了
分析学号结构
我做完这些后发现,虽然拿到了这些信息,但是好像没有学号,有好多统一认证都需要学号,所以我又找到一个系统,也是在公众号发现的,一个学习平台,登陆是学号/身份证后六位,还要求不要改密码,这里我们如果拿到学号登陆进入没准能接触到一些漏洞入口
但是现在不知道学号,只能去分析一下学号结构,然后尝试一下爆破这个系统然后登陆,如果登陆成功说明学号正确而且这个系统能登陆成功,如果登陆失败就可能是字典范围小了,或者这个系统可能就是为了安全,某些不允许的时间段内你登陆直接返回登录失败
既然验证思路有了,那我们就得先办法分析学号结构然后构造字典
我先去他的学校官网、公众号找公示的一下信息,看看能不能找到正确的学号。找到了两个表,奖学金获得者,有学号和学院班级信息,根据这些信息来判断:
- 前两位是级数,也就是2023级开头两位就是23
- 第三位应该是学院编号,当时我还纳闷要是真的是只有一位数那这学校学院数量不就最多10个,后来看了下官网,还真只有9个
- 第四五位是专业的号码,在查前面两位单招同学的信息的时候看到了专业前面就是专业号码
- 第六七位是班级号码,比如在8班就是08,这个的范围应该不会很大,总不可能有个专业有大几十班吧
- 第八九位应该就是班级内的号码,可能开学根据成绩排名啥的来决定,其实这里我还没考虑性别,但是查不到什么性别信息,所以直接从00爆到99
现在我们可以开始构造字典了,我这里直接默认单招的学生和正常高考入学的学号是同样的结构,虽然有可能就是一样的,不过我还是假设一下
- 确定是26届入学,开头是26
- 从单招信息来看可以知道录取的专业,从而去官网找是哪个学院,我确定了其中六个学院的号码,所以这一位确定很快
- 这两位也可以确定,专业号码
- 这两位我不知道,所以直接从01爆到15,可能会有很多班,但是我这里先试试到15
- 最后两位直接01到50,我感觉一个班最多也就50来个人,就先试到50
这里是用的脚本:
# generate_dict.py
import sys
sys.stdout.reconfigure(encoding='utf-8')
result = []
for sixth_seventh in range(1, 16): # 01 到 15
for eighth_ninth in range(1, 51): # 01 到 50
number = f"26222{sixth_seventh:02d}{eighth_ninth:02d}"
result.append(number)
with open("dict.txt", "w", encoding="utf-8") as f:
f.write("\n".join(result))
print(f"生成完成,共 {len(result)} 条")这里构造字典后还没完,因为这里不是明文传输的,这里贴一下前端的一点加密代码和请求体:
// 1. 随机生成 16 位的 key
var keys = _this.generatekey(16)
// 2. 将秘钥转换成 Utf8 字节数组
let key = CryptoJS.enc.Utf8.parse(keys);
// 3. 使用 AES 加密 (模式为 ECB,填充方式为 Pkcs7)
var user = CryptoJS.AES.encrypt(_this.loginInfo.userName, key, {
mode: CryptoJS.mode.ECB,
padding: CryptoJS.pad.Pkcs7
});
var psw = CryptoJS.AES.encrypt(_this.loginInfo.password, key, {
mode: CryptoJS.mode.ECB,
padding: CryptoJS.pad.Pkcs7
});{"token":"4YLkaH6IhIYlgSaK","code":"13007","type":3,"username":"OkKXdpV+Hy4s50G7nG6CbQ==","password":"tOSVe6wXErdvDE/Px0Tijg=="}我们铭文输入的用户名和密码,会被进行AES加密后再base64一次,AES加密的key是前端随机生成的16位key,这个key也会在POST请求体里面,那么后端接受到之后base64解码后用这个传入的key进行AES解密,如果没有正确解密,比如key传错了,就会返回用户名或密码不能为空,正确传入但是用户名或密码不对就会返回用户名或者密码错误,加解密逻辑如图: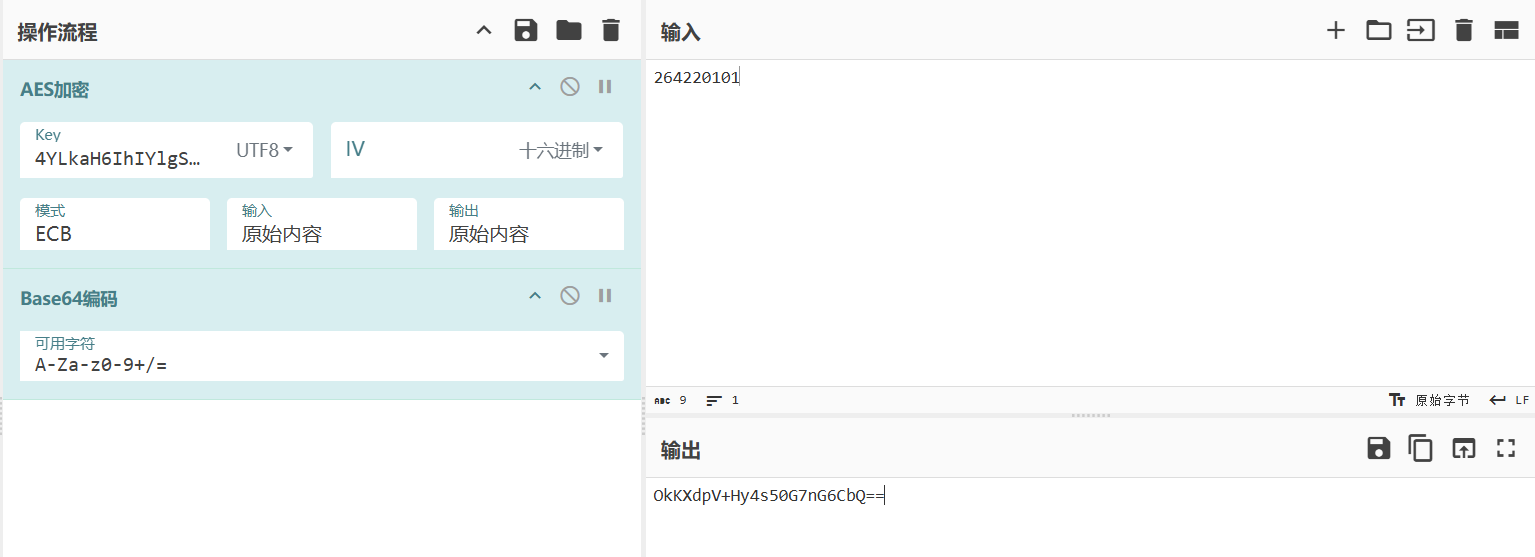
生成的字典内容再加密一次,得到直接贴入burp的字典,以下是脚本:
import base64
from Crypto.Cipher import AES
from Crypto.Util.Padding import pad
import sys
sys.stdout.reconfigure(encoding='utf-8')
def aes_ecb_base64_encrypt(text, key_str):
# 1. 准备 Key
key = key_str.encode('utf-8')
# 2. 初始化 AES ECB 模式
# ECB 模式不需要 IV (初始化向量)
cipher = AES.new(key, AES.MODE_ECB)
# 3. 对明文进行填充 (AES 要求输入必须是 16 字节的倍数,使用 PKCS7)
padded_data = pad(text.encode('utf-8'), AES.block_size)
# 4. 执行 AES 加密
encrypted_data = cipher.encrypt(padded_data)
# 5. 执行 Base64 编码
base64_encoded = base64.b64encode(encrypted_data).decode('utf-8')
return base64_encoded
def process_dictionary(input_file, output_file, key):
try:
with open(input_file, 'r', encoding='utf-8') as f_in, \
open(output_file, 'w', encoding='utf-8') as f_out:
for line in f_in:
# 移除行尾换行符
word = line.strip()
if not word:
continue
# 加密
encrypted_word = aes_ecb_base64_encrypt(word, key)
# 写入新字典,一行一个
f_out.write(encrypted_word + '\n')
print(f"加密完成!结果已保存至: {output_file}")
except Exception as e:
print(f"处理出错: {e}")
# --- 参数配置 ---
# 请将下方的 Key 替换
MY_KEY = "4YLkaH6IhIYlgSaK"
INPUT_DIC = "dict.txt" # 原始字典文件
OUTPUT_DIC = "output.txt" # 加密后的输出文件
if __name__ == "__main__":
process_dictionary(INPUT_DIC, OUTPUT_DIC, MY_KEY)虽然最后没爆出来,可能是字典范围给小了,也可能是单招录取通知发了但是学好还没分配,也可能这系统还没开放啥的,等后面再搞吧,今天就这样,也学习了点社工思路,全程都是纯手打,没有用到任何社工库